The whole idea is similar to Chapter 6, where we extend from MAB to linear bandits to deal with a huge action space. We seek some sort of extension to discrete MDPs in Chapter 6.
Setting
Setting is similar to Chapter 7, i.e., finite horizon+episodic setting+minimize regret
Low-Rank MDPs and Linear MDPs
Here and can be infinite. Without any further structural assumption, the lower bounds we saw in the Generalization Lecture forbid us to get a polynomial regret bound.
Remarks: Remind that in Chapter 7, we have regret bound for UCBVI. If and are infinite/continuous, This is obviously quite bad. Also remind that in Chapter 6, we have regret bound for LinUCB (here is dimension and is iterations). We see the main motivation is that we need to impose some structural assumption, such that we can get a polynomial bound for regret.
The structural assumption we make in this note is a linear structure in both the reward and the transition.
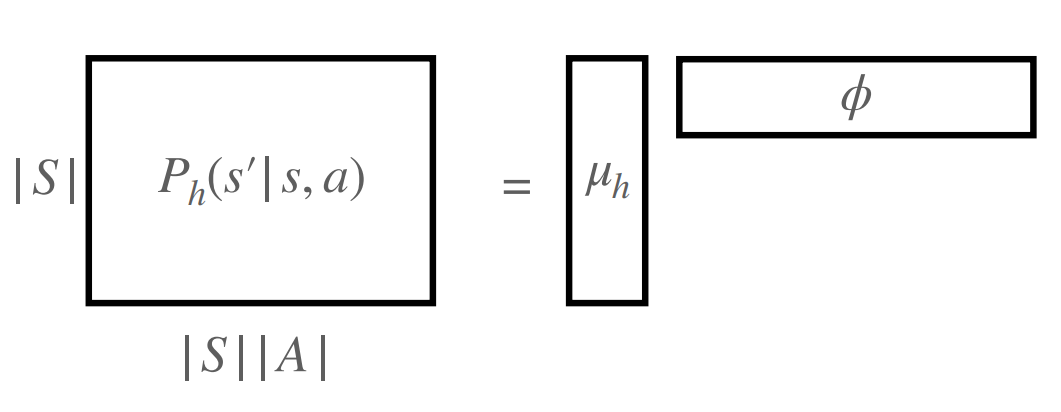
Definition 8.1 (Linear MDPs). Consider transition and . A linear MDP has the following structures on and :
where is a known state-action feature map and Here , are known to the learner, while is unknown. We further assume the following norm bound on the parameters:(1) (2) for any such that , and all , and (3) for all . We assume for all and .
The intuition of this assumption is that now we can have poly() instead of or .
Remarks: The connection to tabular MDPs is that if is a one-hot mapping, then , where denotes the -th column vector and known reward . This reduces to tabular MDPs.
An important observation in linear MDPs is the linearity of everything, i.e.,
where denotes the inner product. And thus we can define and . More generally, we have
Claim 8.2. Consider any arbitrary function At any time step there must exist a, such that, for all
where is the bellman operator.
Proof: derive by definition.
UCBVI?
Learn transmission model from all previous data
Design reward bonus
Plan:
Execute for steps
Remarks: We can see that the general framework is identical, so the point falls on how to design bonus and how to learn the transition kernel.
Learning Transition using Ridge Linear Regression
Remarks: Recall that in tabular MDPs, we use empirical estimation for transition. However, in this setting, this becomes infeasible as and are super big/continuous. So we need a way out.
In this section, we consider the following simple question: given a dataset of state-action-next state tuples, how can we learn the transition for all ?
We consider a particular episode . Similar to Tabular-UCBVI, we learn a model at the very beginning of episode using all data from the previous episodes (episode to the end of episode ). We denote such dataset as:
We maintain the following statistics using :
Remarks: when is a one-hot mapping, the is a diagonal matrix with as elements. (Remind that .)
Remarks: A bound: . The interchange inside the determinant is simply due to and having the same non-zero eigenvalues.
We consider the following multi-variate linear regression problem. Denote as a one-hot vector that has zero everywhere except that the entry corresponding to is one. Denote . Conditioned on history (history denotes all information from the very beginning of the learning process up to and including , we have:
simply because is sampled from conditioned on (Remarks: In other words, ). Also note that for all .
Since , and is an unbiased estimate of conditioned on , it is reasonable to learn via regression from to . This leads us to the following ridge linear regression:
Ridge linear regression has the following closed-form solution:
Note that , so we never want to explicitly store it. Note that we will always use together with a specific pair and a value function (think about value iteration case), i.e., we care about , which can be re-written as:
Thus we only need to compute , which is simply poly(), not depending on .
Lemma 8.3 (Difference between and ). For all and , we must have:
Proof: We start from the closed-form solution of :
Rearrange terms, we conclude the proof.
Lemma 8.4. Fix . For all and , and , with probability at least , we have:
Proof: We first check the noise terms . Since is independent of the data (it's a pre-fixed function), and by linear property of expectation, we have:
Hence, this is a Martingale difference sequence. Using the Self-Normalized vector-valued Martingale Bound (Lemma A.9), we have that for all , with probability at least :
Apply union bound over all , we get that with probability at least , for all :
Uniform Convergence via Covering
The reason to use covering here is that the function class is infinite.
Lemma 8.5. The -covering number of the ball is upper bounded by .
We can extend the above definition to a function class. Specifically, we look at the following function. For a triple of where and , and such that , we define as follows:
We denote the function class as:
Note that contains infinitely many functions as the parameters are continuous. However we will show that it has finite covering number that scales exponentially with respect to the number of parameters in .
Why do we look at ? As we will see later in this chapter contains all possible functions one could encounter during the learning process.
Lemma 8.6 ( -covering dimension of . Consider defined in Eq. 0.6. Denote its -cover as with the norm as the distance metric, i.e., for any . We have that:
Note that the -covering dimension scales quadratically with respect to .
Proof: We start from building a net over the parameter space , and then we convert the net over parameter space to an -net over under the distance metric.
We pick two functions that corresponding to parameters and .
Remarks: Assume , then . Thus we have .
Remarks: The forth line is due to the assumption that .
Note that is a PD matrix with .Now we consider the -Net over -net over interval for , and -net over .
Remarks: This is just the method, covering net version.
The product of these three nets provide a -cover for , which means that that size of the -net for is upper bounded as:
Now we can build a uniform convergence argument for all . Yeyah :) !Lemma 8.7 (Uniform Convergence Results). Set . Fix . For all , all , and all , with probability at least , we have:
Proof: Recall Lemma 8.4 , we have with probability at least , for all , for a pre-fixed (independent of the random process):
where we have used the fact that , and .
Remarks: is the total number of episodes. Note that .
Denote the -cover of as . With an application of a union bound over all functions in , we have that with probability at least , for all , all , we have:
Recall Lemma 8.6, substitute the expression of into the above inequality, we get:
Now consider an arbitrary . By the definition of -cover, we know that for , there exists a , such that . Thus, we have:
where in the second inequality we use the fact that , which is from
Remarks: Remind that , which gives .
Set , we get:
where we recall ignores absolute constants.Now recall that we can express . Recall Lemma 8.3, we have:
Remarks: For the second inequality, we have . Note that since , thus , and assumption 2 yields . (Note that the smallest eigenvalue of .) Since , we obtain the first part of the second inequality. The second part is similar.
Remarks: Note that this is , which will be our bonus term.
Algorithm
Our algorithm, Upper Confidence Bound Value Iteration (UCB-VI) will use reward bonus to ensure optimism. Specifically, we will the following reward bonus, which is motivated from the reward bonus used in linear bandit:
where contains poly of and , and other constants and log terms (). Again to gain intuition, please think about what this bonus would look like when we specialize linear MDP to tabular MDP.
Algorithm 6 UCBVI for Linear MDPs
Input: parameters
for do
Compute for all (Eq. 0.3)
Compute reward bonus for all (Eq. 0.7)
Run Value-Iteration on (Eq. 0.8)
Set as the returned policy of VI.
end for
With the above setup, now we describe the algorithm. Every episode , we learn the model via ridge linear regression. We then form the quadratic reward bonus as shown in Eq. 0.7. With that, we can perform the following truncated Value Iteration (always truncate the function at ):
Note that above contains two components: a quadratic component and a linear component (w.r.t. ). And has the format of defined in Eq. 0.5.
Now we show that falls into the category of :
Lemma 8.8. Assume . For all , we have is in the form of Eq. 0.5, and falls into the following class:
Proof: We just need to show that has its norm bounded. This is easy to show as we always have as we do truncation at Value Iteration:
Remarks: This is from assumption 3.
Now we use the closed-form of from Eq. 0.3:
where we use the fact that , and
Analysis of UCBVI for Linear MDPs
We finally arrive at regret bound!!
In this section, we prove the following regret bound for UCBVI.Theorem 8.9 (Regret Bound). Set . UCBVI (Algorithm 6) achieves the following regret bound:
The main steps of the proof are similar to the main steps of UCBVI in tabular MDPs. We first prove optimism via induction, and then we use optimism to upper bound per-episode regret. Finally, we use simulation lemma to decompose the per-episode regret.In this section, to make notation simple, we set directly.
Proving Optimism
Here we use a different , as the function class is slightly different from the one we use in Lemma 8.7. Check P93 of the book. We denote the event of Lemma 8.7 with .
Lemma 8.10 (Optimism). Assume event is true. for all and ,
Proof: We consider a fixed episode . We prove via induction. Assume that for all . For time step , we have:
where in the last inequality we use the inductive hypothesis that , and is a valid distribution (note that is not necessarily a valid distribution). We need to show that the bonus is big enough to offset the model error . Since we have event being true, we have that:
as by the construction of , we know that .This concludes the proof.
Regret Decomposition
Now we can upper bound the per-episode regret as follows:
We can further bound the RHS of the above inequality using simulation lemma. Recall Eq. 0.4 that we derived in the note for tabular MDP (Chapter 7):
(recall that the simulation lemma holds for any MDPs!
In the event , we already know that for any , we have . Hence, under , we have:
Sum over all episodes, we have the following statement.
Lemma 8.11 (Regret Bound). Assume the event holds. We have:
Conclusion
Lemma 8.12 (Elliptical Potential). Consider an arbitrary sequence of state action pairs . Assume 1. Denote . We have:
Proof: By the Lemma 3.7 and 3.8 in the linear bandit lecture note,
where the first inequality uses that for .
Remarks: We denote as for simplicity. Here we use:
where we use in the last equality. Therefore, we have
which is the second inequality.
Now we use Lemma 8.11 together with the above inequality to conclude the proof.
Now we give the proof of the regret bound.
Proof: [Proof of main Theorem 8.9]We split the expected regret based on the event .
Note that:
Recall that . This concludes the proof.
Remarks: Now we derive a great bound that is , with no dependence on or !